Ampere アーキテクチャに基づく最初の GPU である Nvidia A100 は、OctaneBench プラットフォームで最初のベンチマークを実施したところです。これは当然のことながら、これまでに設計された中で最速の GPU です。テストされたカードは、以前の記録を保持していたタイタン V を 45 ポイント上回っています。 RTX 2080 Ti は 144 ポイント、つまり約 48% 遅れています。この比較は単なる指標であり、2 つのグラフィックス カードは実際には同じカテゴリで動作するわけではありません。

昨年の5月、Nvidia は、Ampere アーキテクチャに基づく最初の GPU である A100 を発表しました。その後同社は、プロ向けセグメント向けの V100 GPU よりも最大 20 倍高いパフォーマンスを発表しました。発表から2ヶ月が経ち、ついに登場です最初の GPU ベンチマークこれにより、そのパフォーマンスの概要がわかります。テストは、3D レンダリング エンジンである OctaneRender のパフォーマンスをテストするために設計されたベンチマークである OctaneBench プラットフォームで実行されました。
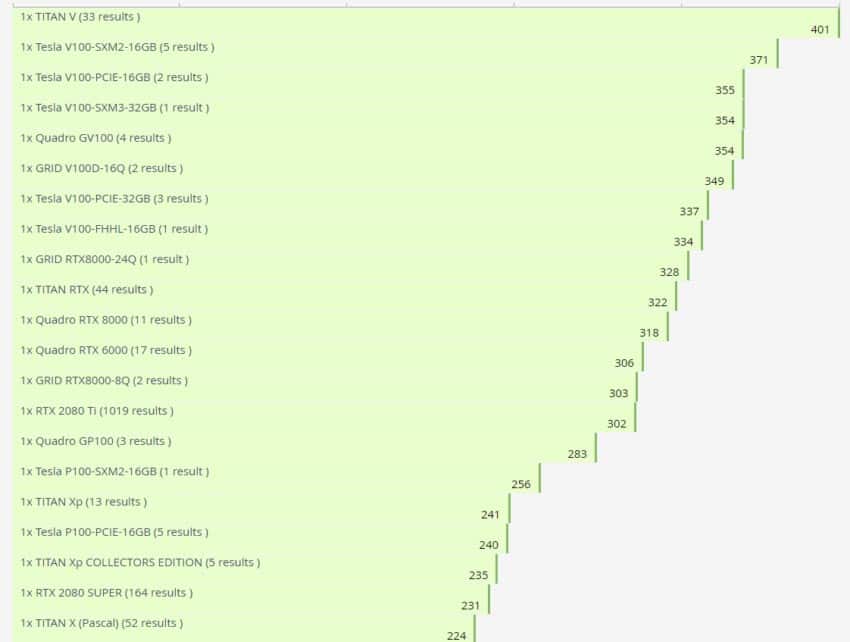
カードは手に入れたスコアは446点平均 401 ポイントを記録した Nvidia Titan V からランキングの首位を奪いました。これは 11.2% の増加に相当します。そこにはGeForce RTX 2080 Ti は 302 ポイントでランキング 14 位です。 A100 は Turing カードよりも約 48% 高速です。より公正に比較すると、GPU は 371 ポイントを記録した Tesla V100 と比較されることになります。したがって、A100 は、実際の前モデルより 18% 高速です。
Ampere A100: そのパフォーマンスは RTX 3000 のパフォーマンスを予測しません
ゲーマーにとって、このベンチマークは将来のパフォーマンスの概要として考慮されるべきではありません。RTX 3000 グラフィックス カードこれらは、同じ Ampere アーキテクチャであっても、同じ用途を意図したものではありません。 RTX 3000 カードはさまざまな GPU を備えており、人工知能の世界向けの A100 GPU と比較してより多くの RT コアを搭載しています。ベックマークも RT コアを無効にして実行されました。
念のために言っておきますが、A100 GPU は 826 mm² の表面積に 540 億個のトランジスタを搭載したモンスターです。 7nm で製造されたこのチップには、40 GB の HBM2 VRAM でサポートされる 6912 個の CUDA コアと 432 個の Tensor コアが搭載されています。比較用次期 RTX 3080 Ti グラフィックス カード5376 CUDA コアと 12 GB の GDDR6x VRAM が搭載されます。
ソース :ツイークタウン




