人工知能のトレーニングに必要な Android ユーザー データの収集をめぐる論争を解決するために、Google は機械学習への新しいアプローチを採用することを決定しました。 Federated Learning と呼ばれるこの技術により、アルゴリズム トレーニング プロセスをユーザーのスマートフォン上で直接実行できます。
これまで、Google は Android をより賢くするために、次のプロセスを使用していました。クラウド上での一元的な機械学習。すべてのユーザー データはクラウド上に収集され、人工知能アルゴリズムはこのデータを使用してトレーニングされます。
この方法は効果的ですが、アプリケーションの更新とユーザー データの取得に時間がかかります。このプロセスはスマートフォンのバッテリー寿命も消費します。さらに、この企業はユーザーがアプリケーションをどのように使用するかに関するデータを自社のクラウド サーバーに保存する以外に選択肢がないため、このやり方では機密保持の点で問題が生じます。
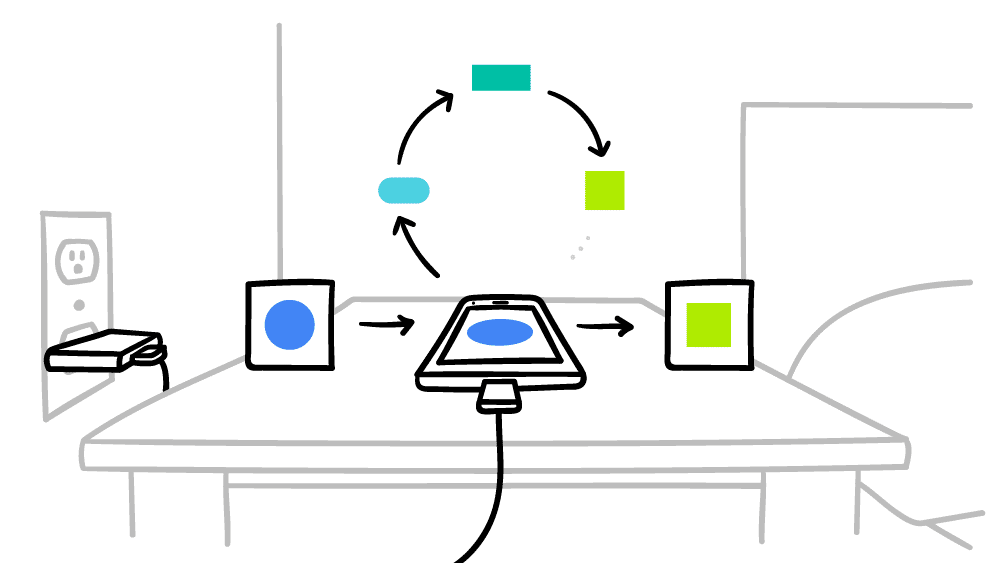
これらのさまざまな問題を解決するために、Google はアルゴリズムをトレーニングする新しい方法である Federated Learning を実験することにしました。この新しいアプローチは次のとおりです。人工知能のトレーニングを分散化する。ユーザーデータをクラウド上に集約するのではなく、収集とトレーニングのプロセスはユーザーのスマートフォン上で直接実行されます。
現在、Googleは実験を開始していますGboard の Federated Learning の詳細。 Gboard がユーザーの投稿に基づいて Google 検索の候補を提供すると、アプリはどの候補が選択され、どれが無視されたかを記憶します。
Android: Federated Learning、機械学習へのより機密性の高いアプローチ
この情報は、ユーザーのスマートフォン上でアプリケーションのアルゴリズムを直接パーソナライズするために使用されます。 AI がトレーニングできるようにするために、Google は機械学習ソフトウェアの軽量バージョンを組み込みました。TensorFlow、Gboard アプリケーションの使用。
次に、変更内容は Google に送信され、Google はすべてのユーザーのアプリケーションを更新できるようになります。つまり、学習プロセスは 2 つの段階に分かれています。
Google が説明しているように、このアプローチは機密性が高く、高速です。ユーザーのデータはスマートフォンから離れることがないため、ユーザーはアップデートを待つ必要がなくなりました。もちろん、同社はまず、Federated Learning がスマートフォンの自律性やパフォーマンスを低下させないことを確認しました。トレーニングは、デバイスがプラグインされ、WiFi 経由で接続されている場合にのみ行われます。
![[チュートリアル] Wifi Direct 経由でファイルを送受信する方法](https://yumie.trade/statics/image/placeholder.png)

